Open source is a distributed innovation model that lacks distributed funding. It allows individuals with a common passion to collaborate and produce value but not capture it. It is a production factory, without a sales counter. That is why many open source contributors are not getting a fair return. That is why many companies capture value from open source but without paying back. That is why many independent open source builders use alternative means to fund themselves. That is why open source is not a business model. It is a production model, monetization not-included. But there is hope, there is change.
Open source monetization journey for individuals
Open source is an innovation model and it is going to innovate its monetization too. There are new ways for fans to support the creative work of open source builders. There are ways to create online courses and monetize knowledge. There are new ways to create digital goods with accompanying services and sell them online for a fiver. Ways to start newsletters and make money from your audience. Ways to measure an open source contributor's merit, incentivize it, and trade it. Decentralized protocols for staking tokens and support open source through interest rather than donations.
99 Ways to Make Money with Open Source as an Individual
There is an open source monetization revolution happening right now and I'll explore the whole spectrum of open source monetization projects at Open Core Summit Digital. Join me on December 16th-18th where I will talk about "99 Ways to Make Money with Open Source as an Individual".
There is a rise in offerings of free educational content, free software, free cloud resources with the single goal of capturing the new kingmaker's attention. In a similar spirit, here I want to quickly share my favorite Kubernetes related books offered free of charge. I've read and found them all very useful at different stages of my learning. The list contains books that are sponsored and offered free of charge but in most cases that is for exchange of your contact details. If you prefer not to give your details, you can go to Amazon, buy the data-capture-free book instead, and support the authors (such as me). I think it is a privilege to work in this industry and I'm thankful for these authors and companies offering the choice of free-of-charge books. Enjoy the list, and don’t come back here saying “This is not free…why are you saying it is free... blah-blah". Here are my best of Kubernetes free picks, happy learning.
Here are also SRE Books you can read online for free:
SRE Books by Google
There are also other honorable mentions, but these are shorter editions (less than 100 pages) and for me these qualify as books written with marketing in mind. Yet I found these books useful and a great value for money ;)
When I was at university, I had to pick between Java and .Net to direct my career. At the time, there were tons of Java books, docs, and even IDEs for free. But only very few .Net books and tools for Microsoft's environments and all of them were expensive for me. Living in a 3rd world country, I made my decision based on available free learning resources.
Lack of attention
Today, we live in a different world. There is an endless amount of resources for learning, from blog posts, tutorials, and online training, all for free. Not only that, companies in a desire to establish themselves as leaders around a tech domain, sponsor quality books, swags and give them for free (some, in exchange for your contact details). Software is developed as open source, enabling collaboration, but more importantly, it allows developer adoption and talent recruiting. Meetups and developer conferences (although now virtual) are all about entertaining developers in an attempt to make them try and like a tech i.e. product. All development tools, enterprise software packages are offered for free for developers. Cloud providers give free-forever resources. All, in the name of attracting the new kingmakers' attention.
Lack of intensives
I say free is not good enough. Free books, free tools, free cloud resources are not good enough. Free pizza and drinks, free stickers, and a t-shirt are not good enough either. You can give your time, but you can never get it back. And if companies want to get the developers’ time, they will have to pay for it. The price of free is your time. If a company wants their story and vision heard by developers, they have to pay for it. If a company wishes to have their free and open source software tried out, they will have to pay for it. If a company wants their tools and services learned, used, adopted, they have to pay for it.
Free is too expensive
The biggest impact on the value and the success of technology is defined by its adoption. The equivalent of adoption in the open source tech world is the community. Any project that has a large community can take over other projects and enable value capture to companies. You are not building only software, you are building software with a community. To build a community, to get peoples' attention and time in the first place, you have to pay for it.
Today, the best example for incentivizing communities, and building communities is the blockchain space. Whether that is through free token distribution to early users, referral programs, through airdrops, bounties for bug fixes, competitions, badges, community tasks, participation in beta programs, etc. blockchain projects offer a value exchange for community attention. Whether the majority of these blockchain projects are a scam or not is a different topic and irrelevant here. But the fact that blockchain projects value community building, user adoption, and they know how to bootstrap projects with communities from zero is undeniable. We need similar mechanisms tailored for developers and general technology adoption. We need to value and pay for the new kingmakers' time and attention. We need to pay them to listen to our vision, learn and to try out our products. If you pay, they will come (and give a try to your software the least).
Thank you for giving a few minutes of your time and attention, for free.
The term asynchronous means “not occurring at the same time” and in the context of distributed systems and messaging it implies that the processing of a request occurs at an arbitrary point in time. There are many advantages of asynchronous interactions over synchronous ones but also new challenges introduced by it. In this post, we will focus on a few specific considerations for choosing a suitable asynchronous messaging infrastructure for implementing event-driven systems. Let’s see a few of the subtle differences between asynchronous interaction styles.
Message Business Value
Not all messages are created equal. Some are valid and valuable only for a short period of time and obsolete later. Some are valuable until they are consumed regardless of the time passed. And some messages are valid and useful for repeated consumption. Considering the validity and the value of messages relative to time and consumption rate, we can qualify interaction styles between services into the following categories:
Message types by business value
Volatile
These are ephemeral messages where the value is time-bound. Valuable now, but not in the short future. There is no point in storing events that are useless in the future and using messaging systems with such characteristics gives the best performance with the lowest latency possible as the disk is skipped. In such a scenario, the system is aware of the connected consumers and the event disseminated to all consumers online at the time of publication. If a consumer is disconnected, the messaging system forgets about these consumers. What is important in such a system is the ability to handle a large number of dynamic clients with low latency interaction needs such as IoT devices.
Durable
However, in some situations you want the messaging system to be aware of the consumers and store the messages while the consumer is not available. That is a traditional message broker which will hold on to the messages for the consumers that he knows about and allow the consumers to re-connect and consume the events that were produced in his absence. Once an event is consumed by all the interested parties, it will discard the messages. Here the broker knows about registered consumers and messages are stored durably until read by all registered consumers. Here the goal is to do reliable messaging among services with strong ordering and delivery guarantees.
Replayable
Here, the messaging system is not aware of the consumers that are interested in the event. It simply stores the events published to a stream for some time or until capacity is reached. Then a consumer can come along at any time, connect and consume the events and perhaps replay the stream from the beginning. Consumers can move back and forth in the stream as required and replay the messages repeatedly. Here, the driving force is extreme scalability combined with the ability to replay messages for existing or new consumers.
Message Semantics
Apart from the technical characteristics of the messages, it is important to distinguish the language we use, the semantic aspects, and the intent of the interactions. Some messages are targeted for a specific consumer and demand concrete actions. Some are querying the latest state of a system without requiring a state change. And some notify the world about a change that has happened in the source system. From a messaging semantic perspective, there are the following types of messages:
Message types by semantics
Command
A command is a request for action that usually leads to a state change on a known target system. Typically there is a response indicating that action was completed and even there might be a result associated with it. When a response is expected, commands are typically implemented over synchronous protocols such as HTTP, but it is possible to implement request/response or fire and forget style commands over asynchronous messaging systems. With a command based asynchronous messages, there is some coupling between the source and the target systems in the form of command semantics.
Query
A query is like a command, but it is a read-only interaction that does not lead to a state change. By its very nature, a query expects a response, and it is common to see synchronous implementations here. But asynchronous and non-blocking implementations over messaging systems and even fire and forget style interactions for long-running operations where a response is written to a different location are common too.
Event
An event is a notification that something has changed. A system sends event notifications to notify other systems for a change in its domain. An event is different from a command in that often the event emitting system doesn’t expect an answer at all. In addition to being asynchronous, event messages are not targeted to a specific recipient and thus, they enable even further decoupling. Similar to other asynchronous interactions, events are implemented as messages on queues, which are often called streams. Martin Fowler covers in-depth the different types of events in this talk.
Summary
One approach you can take is to follow the Law of the Instrument approach defined by Maslow as “If the only tool you have is a hammer, treat everything as if it were a nail." You could certainly use a classic message broker such as Apache ActiveMQ to implement the different interaction styles. It would be a familiar technology to many and easier to start with, but hard to implement some use cases such as replayable messaging. Or you could take the other extreme and try to use Apache Kafka for everything. It would require a larger amount of hardware resources and human effort to manage it, but it would cover the replayable messaging and extreme scalability needs. While both of the above approaches are fine to start with, when you have a large number of services with different messaging needs, using the right tool for the right job is a better option. We can map the above-described messaging patterns to see what messaging infrastructure is best suited for each.
Mapping messaging subtleties to different messaging infrastructures
We at Red Hat love any open source technology. That is why we included Apache Qpid, Apache ActiveMQ Artemis, and Apache Kafka in our Red Hat AMQ product and let the customer choose the right tool for the right job. There are many other aspects to consider when choosing the right tool, I hope this post will help you get there one step closer.
This post was originally published on Red Hat Developers. To read the original post, check here.
This is a guest post by freelance editor and copywriter Laila Mahran.
When using Application Performance Monitoring, you’re able to monitor key app performance metrics about the performance of a web application in production. APM is often thought of as a ‘second wave’ of performance monitoring techniques, which was preceded by traditional host-based monitoring. Let’s dive in more.
Host-based monitoring focuses on indicators such as:
Storage
Memory
CPU
Network utilization
Application monitoring goes a step further and focuses on the actual “end-user” metrics of an application in real-time such as:
Code-level errors
Slowdowns in response times
Error rates
How does this APM magic work?
There are multiple different ways Application Performance Monitoring tools can function. Let’s look at the most common ways APM is used.
An agent process that is deployed alongside a web application that hooks into the application runtime to collect telemetry data from the process
Specialized web appliances that inspect Layer 7 traffic to generate telemetry
When combined with the monitoring mechanism, an external application generates synthetic traffic which is then sent to the application to monitor performance at predefined throughput intervals. When looking at APM tools and other monitoring types, the main difference to highlight is that the telemetry data is generated by inspecting the application runtime, and the performance metrics that it exposes.
Can APM help me?
Traditional host monitoring can make you feel stuck with no step closer to an answer. Application Performance Monitoring is designed to answer questions that you can’t get an answer to. While understanding the raw resource utilization of your application is useful, it doesn’t give you a lot of information when you’re trying to track down why a specific request has high latency, why a particular transaction against your database is failing, or how your application performs under load. Let’s take a look at common questions asked on a daily basis.
What are the implications of this issue on user experience for end users?
Where is this high latency coming from?
What caused that outage?
Why are we getting an error here?
Why is this transaction failing?
Can we find the root cause of this substandard user experience?
Have you asked yourself these questions before? If you’re nodding your head furiously, you can look to APM to provide the answer.
Monitoring vs. Management: What’s the difference?
Application Performance Management applies to a suite of applications while Application Performance Monitoring applies to a single application. An application performance management tool is able to aggregate and compare multiple types of metrics across multiple applications and services in order to pinpoint performance issues and regressions in your suite of applications. On the other hand, Application Performance Monitoring looks at the code-level to ensure each step is monitored thoroughly.
Is Network Monitoring different?
Network monitoring focuses on routers in order to detect issues with an application or collecting telemetry from network devices such as switches. If you’re looking to get a complete picture, networking monitoring requires stitching together information from each line. This approach doesn’t provide sufficient resolution or information for modern applications, however, especially when the application itself may be running behind a variety of proxies or service routers which themselves are running on virtualized networking equipment.
APM vs. Observability: What’s the difference?
You’ve heard the hype of observability, but how is it different from APM? Observability is a holistic approach to fully understanding your application performance as well as a shared set of practices and terminology to help communicate performance across your organization. While observability helps you navigate from effect to cause, APM falls short of being able to answer “unknown unknowns,” questions that you didn’t think to ask ahead of time. This is the reason behind APM currently being eclipsed by observability. Observability is unique due to the capability of answering questions about modern, microservice-based application architectures where you will often contend with serverless components, polyglot services, and container-based deployments running on Kubernetes. Circling back, observability provides a shared language to standardize communication around performance. This way you’re able to focus on the measurement of service level objectives and service level indicators that are more broadly applicable and interpretable to your unique application architecture than simple throughput or health checks.
Is Application Performance Monitoring worth it?
Instead of depending on the second or third order metrics about host or network utilization to understand your application’s performance, APM collects real-time performance data from the perspective of an end-user. Another bonus: real-time results of database queries and page load times are provided with APM in a way that’s not possible with host-based monitoring. This information can be invaluable in understanding how your application performs under load or while trying to track down bugs in your software. APM solutions provide alerting systems to IT Operations, Site Reliability Engineers, DevOps, and more to quickly troubleshoot performance issues and slowdowns.
Today’s developers are expected to develop resilient and scalable
distributed systems. Systems that are easy to patch in the face of
security concerns and easy to do low-risk incremental upgrades. Systems
that benefit from software reuse and innovation of the open source
model. Achieving all of this for different languages, using a variety of
application frameworks with embedded libraries is not possible.
Recently I’ve blogged
about “Multi-Runtime Microservices Architecture” where I have explored
the needs of distributed systems such as lifecycle management, advanced
networking, resource binding, state abstraction and how these
abstractions have been changing over the years. I also spoke about “The
Evolution of Distributed Systems on Kubernetes” covering how Kubernetes
Operators and the sidecar model are acting as the primary innovation
mechanisms for delivering the same distributed system primitives.
On both occasions, the main takeaway is the prediction that the
progression of software application architectures on Kubernetes moves
towards the sidecar model managed by operators. Sidecars and operators
could become a mainstream software distribution and consumption model
and in some cases even replace software libraries and frameworks as we
are used to.
The sidecar model allows the composition of applications written in
different languages to deliver joint value, faster and without the
runtime coupling. Let’s see a few concrete examples of sidecars and
operators, and then we will explore how this new software composition
paradigm could impact us.
Out-of-Process Smarts on the Rise
In Kubernetes, a sidecar is one of the core design patterns
achieved easily by organizing multiple containers in a single Pod. The
Pod construct ensures that the containers are always placed on the same
node and can cooperate by interacting over networking, file system or
other IPC methods. And operators
allow the automation, management and integration of the sidecars with
the rest of the platform. The sidecars represent a language-agnostic,
scalable data plane offering distributed primitives to custom
applications. And the operators represent their centralized management
and control plane.
Let’s look at a few popular manifestations of the sidecar model.
Envoy
Service Meshes such as Istio, Consul, and others are using transparent service proxies such as Envoy
for delivering enhanced networking capabilities for distributed
systems. Envoy can improve security, it enables advanced traffic
management, improves resilience, adds deep monitoring and tracing
features. Not only that, it understands more and more Layer 7 protocols
such as Redis, MongoDB, MySQL and most recently Kafka. It also added
response caching capabilities and even WebAssembly support that will
enable all kinds of custom plugins. Envoy is an example of how a
transparent service proxy adds advanced networking capabilities to a
distributed system without including them into the runtime of the
distributed application components.
Skupper
In addition to the typical service mesh, there are also projects, such as Skupper,
that ship application networking capabilities through an external
agent. Skupper solves multicluster Kubernetes communication challenges
through a Layer 7 virtual network and offers advanced routing and
connectivity capabilities. But rather than embedding Skupper into the
business service runtime, it runs an instance per Kubernetes namespace
which acts as a shared sidecar.
Cloudstate
Cloudstate
is another example of the sidecar model, but this time for providing
stateful abstractions for the serverless development model. It offers
stateful primitives over GRPC for EventSourcing, CQRS, Pub/Sub,
Key/Value stores and other use cases. Again, it an example of sidecars
and operators in action but this time for the serverless programming
model.
Dapr
Dapr
is a relatively young project started by Microsoft, and it is also
using the sidecar model for providing developer-focused distributed
system primitives. Dapr offers abstractions for state management,
service invocation and fault handling, resource bindings, pub/sub,
distributed tracing and others. Even though there is some overlap in the
capabilities provided by Dapr and Service Mesh, both are very different
in nature. Envoy with Istio is injected and runs transparently from the
service and represents an operational tool. Dapr, on the other hand,
has to be called explicitly from the application runtime over HTTP or
gRPC and it is an explicit sidecar targeted for developers. It is a
library for distributed primitives that is distributed and consumed as a
sidecar, a model that may become very attractive for developers
consuming distributed capabilities.
Camel K
Apache Camel is a mature integration library that rediscovers itself on Kubernetes. Its subproject Camel K
uses heavily the operator model to improve the developer experience and
integrate deeply with the Kubernetes platform. While Camel K does not
rely on a sidecar, through its CLI and operator it is able to reuse the
same application container and execute any local code modification in a
remote Kubernetes cluster in less than a second. This is another example
of developer-targeted software consumption through the operator model.
More to Come
And these are only some of the pioneer projects exploring various
approaches through sidecars and operators. There is more work being done
to reduce the networking overhead introduced by container-based
distributed architectures such as the data plane development kit (DPDK),
which is a userspace application that bypasses the layers of the Linux
kernel networking stack and access directly to the network hardware.
There is work in the Kubernetes project to create sidecar containers with more granular lifecycle guarantees. There are new Java projects based on GraalVM implementation such as Quarkus
that reduce the resource consumption and application startup time which
makes more workloads attractive for sidecars. All of these innovations
will make the side-car model more attractive and enable the creation of
even more such projects.
Sidecars providing distributed systems primitives
I’d not be surprised to see projects coming up around more specific
use cases such as stateful orchestration of long-running processes such
as Business Process Model and Notation (BPMN) engines in sidecars. Job
schedulers in sidecars. Stateless integration engines i.e. Enterprise
Integration Patterns implementations in sidecars. Data abstractions and
data federation engines in sidecars. OAuth2/OpenID
proxy in sidecars. Scalable database connection pools for serverless
workloads in sidecars. Application networks as sidecars, etc. But why
would software vendors and developers switch to this model? Let’s see a
few of the benefits it provides.
Runtimes with Control Planes over Libraries
If you are a software vendor today, probably you have already
considered offering your software to potential users as an API or a
SaaS-based solution. This is the fastest software consumption model and a
no-brainer to offer, when possible. Depending on the nature of the
software you may be also distributing your software as a library or a
runtime framework. Maybe it is time to consider if it can be offered as a
container with an operator too. This mechanism of distributing software
and the resulting architecture has some very unique benefits that the
library mechanism cannot offer.
Supporting Polyglot Consumers
By offering libraries to be consumable through open protocols and
standards, you open them up for all programming languages. A library
that runs as a sidecar and consumable over HTTP, using a text format
such as JSON does not require any specific client runtime library. Even
when gRPC and Protobuf are used for low-latency and high-performance
interactions, it is still easier to generate such clients than including
third party custom libraries in the application runtime and implement
certain interfaces.
Application Architecture Agnostic
The explicit sidecar architecture (as opposed to the transparent one)
is a way of software capability consumption as a separate runtime
behind a developer-focused API. It is an orthogonal feature that can be
added to any application whether that is monolithic, microservices,
functions-based, actor-based or anything in between. It can sit next to a
monolith in a less dynamic environment, or next to every microservice
in a dynamic cloud-based environment. It is trivial to create sidecars
on Kubernetes, and doable on many other software orchestration platforms
too.
Tolerant to Release Impedance Mismatch
Business logic is always custom and developed in house. Distributed
system primitives are well-known commodity features, and consumed
off-the-shelf as either platform features or runtime libraries. You
might be consuming software for state abstractions, messaging clients,
networking resiliency and monitoring libraries, etc. from third-party
open source projects or companies. And these third party entities have
their release cycles, critical fixes, CVE patches that impact your
software release cycles too. When third party libraries are consumed as a
separate runtime (sidecar), the upgrade process is simpler as it is
behind an API and it is not coupled with your application runtime. The
release impedance mismatch between your team and the consumed 3rd party
libraries vendors becomes easier to manage.
Control Plane Included Mentality
When a feature is consumed as a library, it is included in your
application runtime and it becomes your responsibility to understand how
it works, how to configure, monitor, tune and upgrade. That is because
the language runtimes (such as the JVM) and the runtime frameworks (such
as Spring Boot or application servers) dictate how a third-party
library can be included, configured, monitored and upgraded.
When a software capability is consumed as a separate runtime (such as a
sidecar or standalone container) it comes with its own control plane in
the form of a Kubernetes operator.
That has a lot of benefits as the control plane understands the
software it manages (the operand) and comes with all the necessary
management intelligence that otherwise would be distributed as
documentation and best practices. What’s more, operators also integrate
deeply with Kubernetes and offer a unique blend of platform integration
and operand management intelligence out-of-the-box. Operators are
created by the same developers who are creating the operands, they
understand the internals of the containerized features and know how to
operate the best. Operators are executables SREs in containers, and the number of operators and their capabilities are increasing steadily with more operators and marketplaces coming up.
Software Distribution and Consumption in the Future
Software Distributed as Sidecars with Control Planes
Let’s say you are a software provider of a Java framework. You may
distribute it as an archive or a Maven artifact. Maybe you have gone a
step further and you distribute a container image. In either case, in
today’s cloud-native world, that is not good enough. The users still
have to know how to patch and upgrade a running application with zero
downtime. They have to know what to backup and restore its state. They
have to know how to configure their monitoring and alerting thresholds.
They have to know how to detect and recover from complex failures. They
have to know how to tune an application based on the current load
profile.
In all of these and similar scenarios, intelligent control planes in
the form of Kubernetes operators are the answer. An operator
encapsulates platform and domain knowledge of an application in a
declaratively configured component to manage the workload.
Sidecars and operators could become a mainstream software
distribution and consumption model and in some cases even replace
software libraries and frameworks as we are used to.
Let’s assume that you are providing a software library that is
included in the consumer applications as a dependency. Maybe it is the
client-side library of the backend framework described above. If it is
in Java, for example, you may have certified it to run it on a JEE
server, provided Spring Boot Starters, Builders, Factories, and other
implementations that are all hidden behind a clean Java interface. You
may have even backported it to .Net too.
With Kubernetes operators and sidecars all of that is hidden from the
consumer. The factory classes are replaced by the operator, and the
only configuration interface is a YAML file for the custom resource. The
operator is then responsible for configuring the software and the
platform so that users can consume it as an explicit sidecar, or a
transparent proxy. In all cases, your application is available for
consumption over remote API and fully integrated with the platform
features and even other dependent operators. Let’s see how that happens.
Software Consumed over Remote APIs Rather than Embedded Libraries
One way to think about sidecars is similar to the composition over inheritance principle
in OOP, but in a polyglot context. It is a different way of organizing
the application responsibilities by composing capabilities from
different processes rather than including them into a single application
runtime as dependencies. When you consume software as a library, you
instantiate a class, call its methods by passing some value objects.
When you consume it as an out-of-process capability, you access a local
process. In this model, methods are replaced with APIs, in-process
methods invocation with HTTP or gRPC invocations, and value objects with
something like CloudEvents. This is a change from application servers
to Kubernetes as the distributed runtime. A change from
language-specific interfaces, to remote APIs. From in-memory calls to
HTTP, from value objects to CloudEvents, etc.
This requires software providers to distribute containers and
controllers to operate them. To create IDEs that are capable of building
and debugging multiple runtime services locally. CLIs for quickly
deploying code changes into Kubernetes and configuring the control
planes. Compilers that can decide what to compile in a custom
application runtime, what capabilities to consume from a sidecar and
what from the orchestration platform.
Software consumers and providers ecosystem
In the longer term, this will lead to the consolidation of
standardized APIs that are used for the consumption of common primitives
in sidecars. Rather than language-specific standards and APIs we will
have polyglot APIs. For example, rather than Java Database Connectivity
(JDBC) API, caching API for Java (JCache), Java Persistence API (JPA),
we will have polyglot APIs over HTTP using something like CloudEvents.
Sidecar centric APIs for messaging, caching, reliable networking, cron
jobs and timer scheduling, resource bindings (connectors to other APIs,
protocols), idempotency, SAGAs, etc. And all of these capabilities will
be delivered with the management layer included in the form of operators
and even wrapped with self-service UIs. The operators are key enablers
here as they will make this even more distributed architecture easy to
manage and self-operate on Kubernetes. The management interface of the
operator is defined by the CustomResourceDefinition and represents
another public-facing API that remains application-specific.
This is a big shift in mentality to a different way of distributing
and consuming software, driven by the speed of delivery and operability.
It is a shift from a single runtime to multi runtime application
architectures. It is a shift similar to what the hardware industry had
to go through from single-core to multicore platforms when Moore’s law
ended. It is a shift that is slowly happening by building all the
elements of the puzzle: we have uniformly adopted and standardized
containers, we have a de facto standard for orchestration through
Kubernetes, possibly improved sidecars coming soon, rapid operators
adoption, CloudEvents as a widely agreed standard, light runtimes such
as Quarkus, etc. With the foundation in place, applications,
productivity tools, practices, standardized APIs, and ecosystem will
come too.
This post was originally published at The New Stack here.
As an architect in the Red Hat Consulting team, I’ve helped countless customers with their integration challenges over the last six years. Recently, I had a few consulting gigs around Red Hat AMQ 7 Broker (the enterprise version of Apache ActiveMQ Artemis), where the requirements and outcomes were similar. That similarity made me think that the whole requirement identification process and can be more structured and repeatable.
This guide is intended for sharing what I learned from these few gigs in an attempt to make the AMQ Broker architecting process, the resulting deployment topologies, and the expected effort more predictable—at least for the common use cases. As such, what follows will be useful for messaging and integration consultants and architects tasked with creating a messaging architecture for Apache Artemis, and other messaging solutions in general. This article focuses on Apache Artemis. It doesn’t cover Apache Kafka, Strimzi, Apache Qpid, EnMasse, or the EAP messaging system, which are all components of our Red Hat AMQ 7 product offering.
Typical customer requirements
In my experience, a typical middleware use case has fairly basic messaging requirements and constraints that fall under a few general categories. Based on the findings in these areas, there are a few permutations of the possible solutions with pros and cons, and the final resulting architectures are fairly common. Designing, documenting, communicating the constraints and implementing these common architectures, should be well understood by messaging SMEs. Anything different from these standard architectures should be expected to require additional effort and lead to a bespoke architecture with unique non-functional and operational characteristics.
This article covers the following hypothetical but common messaging scenario. Here is a customer describing the typical messaging requirements:
We have around 100 microservices with Spring Boot and Apache Camel that use messaging extensively.
All of our services are scalable and high availability (HA), and we expect the messaging layer to have similar characteristics.
We use mostly point-to-point but we also have a few publish-subscribe interactions.
Most of our messages are small in the KB range, but there are those that are fairly large in the single-digit MBs range.
We don’t know our current message throughput, it changes as we add new services using messaging.
We don’t use any exotic features, but we have use cases with message selectors, scheduled delivery, and TTL.
We need to preserve the message ordering with and without message grouping.
We primarily use JMS from our Java-based services and AMQP from the few .NET services.
We don’t like XA, but in a handful of services, we use distributed transactions involving the message broker.
We can replay messages if necessary, but we cannot lose any message, and we use only persistent messages.
We put all failed messages in DLQs and discard later.
We want to know all of the best practices and naming conventions.
All broker-to-broker communication and client-to-broker communication must be secured.
We want to control who can create queues, read and write messages, and browse.
If you hear these above requirements, you are in familiar territory, and this article should be useful to you. If not, and there are specific hardware, throughput, topological, or other requirements, clone the Apache Artemis repo and go deeper. And don’t forget to share what you learn with others later.
The constraints identification approach
In addition to the obvious customer requirements and wishes, other hard and soft constraints will shape the resulting architecture. The customer might or might not be aware of these constraints and dependencies, and it is your job to dig deep and discover them all.
The approach I follow is to start from the fundamental and hard to change requirements, such as infrastructure and storage, as shown in Figure 1. Explore what options there are for each and document the constraints with pros and cons. Then, do the same for the orchestration layer, if present.
The fundamental constraints will then dictate what is possible in the upper layers, such as options for high availability and scalability. Further up in the layers the flexibility increases, and one can choose swap load balancers and different client implementations without impacting the layers below.
Figure 1: Breaking down higher-level requirements into specific constraints.
Finding the answers to these points and identifying what is most important and where the customer is willing to make a compromise will help you identify a workable architecture. Next, let’s go deeper, and see what the specific constraints are for an Apache Artemis-based solution.
Infrastructure
This an area where the customer will have the least amount of flexibility, and your goal is to identify how the message broker fits within the available infrastructure in a reliable configuration. It is unlikely that a customer will change their infrastructure provider for their messaging needs, so try to identify a fit-for-purpose solution.
Typically, common messaging infrastructures are based on on-premise infrastructure with virtualizers, NFS storage, and F5 load balancers. This infrastructure all can be within a single data center or spread across two data centers (rather than three, unfortunately). In an alternative scenario, the customer might be using AWS (or equivalent), such as EC2, EBS, EFS, RDS, or ELBs. Typically, all of these options spread across three AZs in a single region. That is the most common AWS setup for a small-to-midsize integration use case.
Apart from computing, storage, and load balancers, at this stage, we want to identify the data center's topology, network latency, and throughput. Is the client using a single datacenter, two data centers, or any other odd number? Is it an active-active, or active-passive data center topology?
Last but not least, what are the operating system, JDK, and client stacks? This information is easily verifiable from the AMQ 7-supported configuration page, including what is tested, what is supported, for how long, and whatnot.
While on-premise and cloud-based infrastructures offer similar resources, the difference typically is in the number of data centers and the operation, failover, and disaster recovery models. Influencing these fundamental models is a slow process, which is why we want to identify these constraints first.
Storage
Once we have identified the broader infrastructure level details, the next step is to focus on storage. Storage is a part of the infrastructure layer but it requires separate considerations here. When HA is a requirement (which is always the case), storage is the most critical and limiting factor for the messaging architecture. Pay special attention to what options the customer's infrastructure offers, as the answer will significantly limit the possible deployment topologies.
Storage capacity
Capacity is hardly a real issue, as typically there are many unknowns when estimating the exact storage capacity required. Most customers:
Use the message broker as their temporary staging area, where messages are consumed as fast as the consumers can handle. Typically there are no consumer service RPOs defined, and it is not clear for how long messages can keep accumulating.
Put messages into DLQs, but will not have a clear idea of what to do with these messages later. Replaying failed messages is dependent on the actual business requirements and is not always desirable.
Expect that if a message is 1MB in size, it will consume 1MB on the disk. As you all know from experience by now, that is not the case. The same message could end up consuming multiple times more storage, depending on the type of messaging interaction style, caching, and other configurations.
All of these and other scenarios can lead to the accumulation of messages in the broker and consume hundreds of gigabytes of storage. If the customer has no answers to these points, the only proven approach for estimating the required storage size is "finger in the air." Luckily, Artemis—like its predecessors—has flow control, which can protect the broker from running out of storage. This question typically comes down to whether to throw an exception or block the producers to protect the broker.
Storage type
Storage type is much more important and dictates what high-availability options will be required later. For example, if the broker is on Kubernetes, there is no master/slave, and therefore, there is no need for a shared file system with a distributed lock such as NFSv4, GFS2, or GlusterFS. But, the file system should ensure that the journal has high availability.
When the broker is on VMs (not on Kubernetes), the simpler option to implement and operate is to use a supported shared file system. Notice that AWS EFS service is not a full NFSv4 spec, but it is still supported as a shared storage option for Artemis. If a shared file system is not present, alternatively, you can use a relational database as storage with a potential performance hit. Check which relational databases are supported (currently, that is Oracle, DB2, MSSQL). Note that using AWS RDS is a viable option here too.
If no shared file system or relational database is possible, you can consider replication. Replication requires additional considerations. One big advantage of replication is that the messaging and middleware team will not depend on any storage team to provision the infrastructure. Also, there won’t be a cost for shared filesystems or relational databases, and the broker performs its data replication. There are customers who like this aspect, but all good things come at a cost, such as the fact that a reliable replication requires a minimum of three master and three slave brokers to avoid split-brain situations.
There is also the option of using the network pinger, which is risky and not recommended in practice. The network pinger avoids the need for three of everything, but you should only use the network pinger if you are unable to use three or more live backup groups. If you are using the replication high availability policy, and if you have only a single live backup pair, configuring network pinging reduces (but does not remove) the chances of encountering network isolation.
Another cost is that split-brain could happen, not only for network partitions and server crashes, but also as a consequence of overload, CPU starvation, long I/O waits, long garbage collection pauses, and other reasons. Also, replication can happen only within a single datacenter and LAN and requires a reliable, low-latency network. AWS AZs in the same region are considered different data centers, as Amazon does not commit to networking latency SLAs either. Finally, replication also has a performance hit compared to a shared store option.
Ultimately, the critical point about storage is that while we can make the broker process and the client process HA, the datastore itself also has to be HA and durable, and this is possible only through data replication. As part of AMQ architecture, it is important to identify who is replicating the data (the file system, the database, or the message broker itself through replication) to ensure that the data is highly available.
Orchestration
Here, the question boils down to checking whether the customer will run the message broker on container orchestrators such as Kubernetes and Red Hat OpenShift, on bare VMs through homegrown bash scripts, or Red Hat Ansible playbooks. If the customer is not targeting OpenShift, the questions in this section can be skipped. If the messaging infrastructure will run on containers and be orchestrated by Kubernetes, there are a few constraints and architectural implications to consider.
For example, there is no master/slave failover (so no hot backup broker present). Instead, there is a single pod per broker instance that is health monitored and restarted by Kubernetes, which ensures broker HA. The single pod failover process with Kubernetes is different from master/slave with replication failover on-premise. Because there is no master/slave failover, there is no need for message replication between master/slave either. There is also no need for distributed file locking, which means that there is no need for a shared file system with distributed locking capabilities and that one can still use these file systems to mount the same storage to different Kubernetes nodes and pods, but the locking capability of the file system is not a prerequisite any longer.
For example, in the case of a node failure, Kubernetes would start a broker pod on a different node and make the same PV and data available. Because there is no master/slave, there is no need for ReadWriteMany, but only for ReadWriteOnce volume types. That said, you might still need a shared file system that can be mounted to different nodes in the case of node failure (such as AWS EBS, which can be mounted to different EC2 instances in the same region).
So, are there messaging clients located outside of the cluster? Connecting to the broker from within an OpenShift cluster is straightforward through Kubernetes services, but there are restrictions for connecting to the broker from outside of the Kubernetes cluster.
Next, can external clients use a protocol that supports SNI? The easiest option is typically to use SSL and access the broker from the router. If using TLS for clients is not possible, consider using NodePort binding which requires cluster-admin permissions.
Finally, there is a scaledown controller to drain and migrate messages when scaling down broker pods in a cluster.
There might be a few other differences, but failover, discovery, and scaledown is automated, and the broker fundamentals do not change on Kubernetes and Openshift.
High availability
When a customer talks about "high availability," what they mean is a full-stack, highly-available messaging layer. That means HA storage, HA brokers, HA clients, HA load balancers, and HA anything else that might be in between. To cover this scenario, you have to consider the availability of every component in the stack, as shown in Figure 2:
Figure 2: Redundancy at every layer.
Storage
The only way to ensure HA for data is by replicating the data. You have to identify who replicates the data and where the data is replicated: locally, across VMs, across DCs, and so on. Most customers will want to survive a single data center outage without a message loss, which requires a cross data center replication mechanism. The easiest option is to delegate the journal replication to the file system. This option has implications on cost and dependency on infrastructure teams. For example, if you replicate data using a database, consider the cost and performance hit. If you replicate data using Artemis journal replication but consider the customer's maturity to operate a broker cluster, consider split-brain scenarios, data center latencies, and performance hits.
Broker
On Kubernetes, broker HA is achieved through health checks and container restarts. On-premise, the broker HA is achieved through master/slave (shared store or replication). When replication is used, the slave will already hold the queues in memory, and therefore is pretty much ready to go in case of failover. With shared storage, when the slave gets hold of the lock, then the queues need to be read from the journals ahead of the slave takeover. The time for a shared storage slave to take over will be dependent on the number and size of messages in the journal.
When we talk about broker HA, it comes down to an active-passive failover mechanism (with Kubernetes being an exception). But Artemis also has an active-active clustering mechanism used primarily for scalability rather than HA. In active-active clustering, every message belongs to only one broker, and losing an active broker will make its messages also unaccessible—but a positive side effect of that issue is that the broker infrastructure is still up and functioning. Clients can use active instances and exchange messages with the drawback of temporarily not accessing the messages that are in the failed broker. To sum up, active-active clustering is primarily for scalability, but it also partially improves the availability with temporary message unavailability.
Load balancer
If there is a load balancer, prefer one that is already HA in the organization, such as F5s. If Qpid is used, you will need two or more active instances for high availability.
Clients
This is probably the easiest part, as most customers will already run the client services in redundantly HA fashion, which means two or more instances of consumers and producers most of the time. A side effect of running multiple consumers is that message ordering is not guaranteed. This is where message groups and exclusive consumers can be used.
Scalability
Scalability is relatively easier to achieve with Artemis. Primarily, there are two approaches to scaling the message broker.
Active-active clustering
Create a single logical broker cluster that is scaled transparently from the clients. This can be three masters and three slaves (replication or shared storage doesn’t matter) to start with, which means that clients can use any of the masters to produce and consume the messages. The broker will perform load balancing and message distributions. Such a messaging infrastructure is scalable and supports many queues and topics with different messaging patterns. Artemis can handle large and small messages effectively, so there is no need for using separate broker clusters depending on the message size either.
A few of the consequences of active-active clustering are:
Message ordering is not preserved.
Message grouping needs to be clustered.
Scaling down requires message draining.
Browsing the brokers and the queues is not centralized.
Client-side partitioning
Create separate, smaller master/slave clusters for different purposes. You can have a separate master/slave cluster for real-time, batch, small messages, large messages, per business domain, criticality, team, etc. When a broker pair reaches its capacity limit, create a separate broker pair and reconfigure clients to use it.
This technique works as long as the clients can choose which cluster to connect to (hence the name client-side partitioning). There is also a use case here for Apache Qpid where you can add new brokers and assign addresses to them without the clients needing to know anything about the location of these brokers, and therefore, simplifying the clients and making the messaging network dynamic.
Load balancer
While a load balancer is not a mandatory component of the messaging stack, it is an architectural decision whether you are going to use client-side load balancing or an external load balancer. With an external load balancer, you have the fact that customers like using their existing load balancers such as F5 for messaging, too. Plus, load balancers:
Already exist in many organizations, they are already HA, and they support many protocols—so it makes sense to use them for messaging too.
Allow a single IP for all clients.
Can do health checks and failover to the master broker (that is, a probe attempting to connect to the relevant acceptor).
There are clients, such as the .NET client with the AMQP protocol, do not support the failover protocol OOTB (here is also an example showing how to mitigate this limitation). Using a load balancer helps with these clients.
Apache Qpid
Apache Qpid can act as an intelligent load balancer for the AMQP protocol only. It supports closest-, lowest latency-, and multicasting-type distributions. You will need to run multiple instances of Qpid to make it HA. That means the clients have to be configured to use multiple IPs. Qpid can also support many topologies, and allow having connections from more secure to less secure directions rather than the other way.
Qpid comes into its own in a geographically-spread meshing message where clients do not know the location of each other and any of the brokers they might be sending messages to, bi-directional messaging beyond the firewall, and building redundant messaging network routes. It's also easy to scale the number of brokers without changing the clients, and the topology can change without a change to the clients as well (dynamic messaging infrastructure).
You can also use Qpid to create multiple brokers sharding an address without the need to use broker clustering, but this feature is only useful if message ordering is not that important, or to act as a client connection concatenator (especially useful for IoT scenarios).
Client-side load balancing
Using a load balancer is not required in reality. You can configure messaging clients to connect to a broker cluster directly. A client can connect to a single broker and discover all other brokers, changing topologies, etc. Consider what happens if the single broker the client is trying to connect is down. For the answer, a list of broker IPs can be passed, and custom load balancing strategies implemented.
Client-side load balancing has advantages: The client can publish to multiple brokers and perform load balancing. This feature can be disabled if publishing to a single broker is required. The downside here is that the client-side load balancing is a client-specific implementation, and the options mentioned here vary across clients.
Clients
With Artemis, there are multiple clients, protocols, and possible combinations. In terms of protocols, here are a few high-level pointers. Another thing to consider here is which protocol can be converted to which protocols when consumers and producers use different wire protocols and clients. The protocol and client choices are unlikely to impact the broker architecture, but they will impact the client service development efforts, and this issue can easily turn into a mess.
AMQP 1.0
AMQP 1.0 should be the default starting option when possible. This option is one of the most tested and used. It is also cross-language, and the only supported option for .NET clients. Keep in mind that Interconnect (the enterprise version of Apache Qpid) supports AMQP 1.0 only, and if Interconnect is in the architecture, the clients have to use AMQP to interact with it.
A limitation of AMQP is that it does not offer XA transaction support
Core
The Core protocol is one of the most advanced, feature-rich, and tested protocols for Artemis. It is the only supported protocol when using EAP with embedded Artemis, and it is the recommended protocol when XA is required.
OpenWire
This protocol is here for legacy compatibility reasons with AMQ 6 (Apache ActiveMQ broker) clients. It is useful in situations when the client code cannot change, so you are stuck with OpenWire. An attractive point about this protocol is that it supports XA.
Reference architectures
Having identified requirements, dependencies, and specific constraints, the next step is coming up with possible deployment architectures. I’m a firm believer in the mantra, "There is no reference architecture for the real world." Consequently, there is no simple process to follow and map the findings to a target architecture. It is the combination of all requirements, constraints, and possible compromises that lead to identifying the most suitable architecture for a customer.
For demonstration purposes, the following are common Artemis deployment topologies for AWS, on bare VMS instead of Kubernetes. The same topologies also apply for on-premise deployments where similar alternative infrastructure services are present. The considerations that apply to all of the deployments below are:
Client-side load balancing or a load balancer can be used for all of these deployments.
Load balancers can be co-located with the broker, client, in a dedicated layer, or a combination of these.
Slave brokers can be kept in separate hosts as demonstrated below, or co-located with a master broker.
Non-clustered Apache Artemis with shared storage
The simplest HA architecture for Artemis is a single master/slave cluster with shared storage. The example that follows is a scalable version of that set up with two separate master/slave clusters. Notice that there is no clustering (server-side message distribution or load balancing) between the masters. As a result, the clients need to decide which master/slave cluster to use.
Pros
The pros of this approach are:
It is a simple but highly available Artemis configuration and operational model.
It is the same topology as in Apache ActiveMQ with master/slave.
There is no possibility for split-brain, no stuck messages, and message order guaranteed.
Cons
The cons are that this approach requires a shared file system or database, which has an additional cost. Typically, database-based storage is expected to perform worse than file-based storage.
Other notes
Additional notes include the fact that journal high availability is achieved through file system or database (AWS EFS or RDS ) data replication. Optionally, masters can be clustered for message distribution, load balancing, and scalability. The number of master/slave pairs can vary (there are two in Figure 3), and scaling is achieved by adding more master/slave pairs and using client-side partitioning.
Also, in the case of VM or DC failure, it ensures HA.
Figure 3: Apache Artemis with a shared file and database store.
Clustered Apache Artemis with shared storage
In this topology, we have three master/slave pairs, ensuring HA. In addition, all of the masters are clustered and provide server-side load balancing and message distribution. In this setup, the clients can connect to any member of the cluster and exchange messages. Such a cluster can also scale and change topology without affecting client configuration.
Pros
The pros of this option are that it offers:
The same topology as in Apache ActiveMQ with master/slave and Network-of-Brokers.
Server-side message distribution and load balancing.
No possibility for split-brain scenarios.
Cons
The cons are that it requires a shared file system or database, which has an additional cost. Typically, database-based storage is expected to perform worse than file-based storage.
Other notes
With this approach, journal high availability is achieved through file system or database (AWS EFS/RDS ) data replication. Optionally, masters can be non-clustered to prevent server-side load balancing. The number of master/slave pairs can vary (there are three in Figure 4), and scaling is achieved by adding more master/slave pairs transparently to the clients.
Finally, this approach ensures HA in the case of VM or DC failure.
Figure 4: Apache Artemis with a shared file and database store.
Clustered Apache Artemis with replication
This architecture is a variation of the previous one, where we replace shared storage between Master and slave with replication. As such, this architecture has all of the benefits of server-side load-balancing and transparency for the clients. An added benefit of this architecture is that it does not require a highly-available shares storage layer. Instead, the brokers replicate the data.
Pros
The pros of this approach are that:
Data replication is performed by the broker, not by the infrastructure services.
There is no extra cost or dependency on the infrastructure for journal replication.
It offers scalable and highly available messaging infrastructure.
Cons
The cons are that:
Replication is sensitive to network latency, opening the possibility of split-brain scenarios. Notice that the replication in Figure 4 is within the same DC.
Compared to other options, this one has complex configuration and operational models.
It requires a minimum of three master and three slave brokers (as in the diagram below).
Other notes
With this approach:
The number of master/slave pairs can be different (odd number required).
Optionally, server-side message distribution and load balancing can be disabled.
It ensures HA in the case of VM failure, but not in the case of DC failure.
It requires a quorum and a certain number of brokers to be alive.
Figure 5: Apache Artemis with replication.
Capacity planning
The numbers and ranges shown in Figure 5 are provided only as a guide and starting point. Depending on the use case, you might have to scale up or down your individual architectural components.
Figure 5: Example sizing and considerations for the messaging components.
Summary
Over the years, I have hardly seen two messaging architectures that are absolutely the same. Every organization has something unique in the way they manage their infrastructure and organize their teams, and that inevitably ends up reflected in the resulting architectures. Your job as a consultant or architect is to find the most suitable architecture within the current constraints, and educate and guide the customer towards the best possible outcome. There is no right or wrong architecture, but deliberate trade-off commitments in a context.
In this article, I tried to cover as many areas of Artemis as possible from an architecturally significant point of view. But by doing so, I had to be opinionated, ignore other areas, and emphasize what I think is significant based on my experience. I hope you find it useful and learned something from it. If that is the case, say something on Twitter and spread the word. This post was originally published on Red Hat Developers. To read the original post, check here.
Creating good distributed applications is not an easy task: such systems often follow the 12-factor app and microservices principles.
They have to be stateless, scalable, configurable, independently released, containerized, automatable, and sometimes event-driven and
serverless. Once created, they should be easy to upgrade and affordable to maintain in the long term. Finding a good balance among these
competing requirements with today’s technology is still a difficult endeavor.
In this article, I will explore how distributed platforms are evolving
to enable such a balance, and more importantly, what else needs to
happen in the evolution of distributed systems to ease the creation of maintainable distributed architectures. If you prefer to see my talk on this very same topic, checkout my QConLondon recording at InfoQ.
Distributed application needs
For this discussion, I will group the needs of modern distributed
applications into four categories — lifecycle, networking, state,
binding — and analyze briefly how they are evolving in recent years.
Distributed application needs
Lifecycle
Let’s start with the foundation. When we write a piece of functionality,
the programming language dictates the available libraries in the
ecosystem, the packaging format, and the runtime. For example, Java uses
the .jar format, all the Maven dependencies as an ecosystem, and the
JVM as the runtime. Nowadays, with faster release cycles, what’s more
important with lifecycle is the ability to deploy, recover from errors,
and scale services in an automated way. This group of capabilities
represents broadly our application lifecycle needs.
Networking
Almost every application today is a distributed application in some
sense and therefore needs networking. But modern distributed systems
need to master networking from a wider perspective. Starting with
service discovery and error recovery, to enabling modern software
release techniques and all kinds of tracing and telemetry too. For our
purpose, we will even include in this category the different message
exchange patterns, point-to-point and pub/sub methods, and smart routing mechanisms.
State
When we talk about state, typically it is about the service state and
why it is preferable to be stateless. But the platform itself that
manages our services needs state. That is required for doing reliable
service orchestration and workflows, distributed singleton, temporal
scheduling (cron jobs), idempotency, stateful error recovery, caching,
etc. All of the capabilities listed here rely on having state under the
hood. While the actual state management is not the scope of this post,
the distributed primitives and their abstractions that depend on state
are of interest.
Binding
The components of distributed systems not only have to talk
to each other but also integrate with modern or legacy external systems.
That requires connectors that can convert various protocols, support
different message exchange patterns, such as polling, event-driven,
request/reply, transform message formats, and even be able to perform
custom error recovery procedures and security mechanisms.
Without going into one-off use cases, the above represent a good
collection of common primitives required for creating good distributed
systems. Today, many platforms offer such features, but what we are
looking for in this article is how the way we used these features
changed in the last decade and how it will look in the next one. For
comparison, let’s look at the past decade and see how Java-based
middleware addressed these needs.
Traditional middleware limitations
One of the well-known traditional solutions satisfying an older
generation of the above-listed needs is the Enterprise Service Bus (ESB)
and its variants, such as Message Oriented Middleware, lighter
integration frameworks, and others. An ESB is a middleware that enables
interoperability among heterogeneous environments using a
service-oriented architecture (i.e. classical SOA).
While an ESB would offer you a good feature set, the main challenge
with ESBs was the monolithic architecture and tight technological
coupling between business logic and platform, which led to technological
and organizational centralization. When a service was developed and
deployed into such a system, it was deeply coupled with the distributed
system framework, which in turn limited the evolution of the service.
This often only became apparent later in the life of the software.
Here are a few of the issues and limitations of each category of needs that makes ESBs not useful in the modern era.
Lifecycle
In traditional middleware, there is usually a single supported
language runtime, (such as Java), which dictates how the software is
packaged, what libraries are available, how often they have to be
patched, etc. The business service has to use these libraries that
tightly couple it with the platform which is written in the same
language. In practice, that leads to coordinated services and platform
upgrades which prevents independent and regular service and platform
releases.
Networking
While a traditional piece of middleware has an advanced feature set
focused around interaction with other internal and external services, it
has a few major drawbacks. The networking capabilities are centered
around one primary language and its related technologies. For Java
language, that is JMS, JDBC, JTA, etc. More importantly, the networking
concerns and semantics are deeply engraved into the business service as
well. There are libraries with abstractions to cope with the networking
concerns (such as the once-popular Hystrix project), but the library’s
abstractions "leak" into the service its programming model, exchange
patterns and error handling semantics, and the library itself. While it
is handy to code and read the whole business logic mixed with networking
aspect in a single location, this tightly couples both concerns into a
single implementation and, ultimately, a joint evolutionary path.
State
To do reliable service orchestration, business process management,
and implement patterns, such as the Saga Pattern and other slow-running
processes, platforms require persistent state behind the scenes.
Similarly, temporal actions, such as firing timers and cron jobs, are
built on top of state and require a database to be clustered and
resilient in a distributed environment. The main constraint here is the
fact that the libraries and interfaces interacting with state are not
completely abstracted and decoupled from the service runtime. Typically
these libraries have to be configured with database details, and they
live within the service leaking the semantics and dependency concerns
into the application domain.
Binding
One of the main drivers for using integration middleware is the
ability to connect to various other systems using different protocols,
data formats, and message exchange patterns. And yet, the fact that
these connectors have to live together with the application, means the
dependencies have to be updated and patched together with the business
logic. It means the data type and data format have to be converted back
and forth within the service. It means the code has to be structured and
the flow designed according to the message exchange patterns. These are
a few examples of how even the abstracted endpoints influence the
service implementation in the traditional middleware.
Cloud-native tendencies
Traditional middleware is powerful. It has all the necessary
technical features, but it lacks the ability to change and scale
rapidly, which is demanded by modern digital business needs. This is
what the microservices architecture and its guiding principles for
designing modern distributed applications are addressing.
The ideas behind the microservices and their technical requirements
contributed to the popularization and widespread use of containers and
Kubernetes. That started a new way of innovation that is going to
influence the way we approach distributed applications for years to
come. Let’s see how Kubernetes and the related technologies affect each
group of requirements.
Lifecycle
Containers and Kubernetes evolved the way we package, distribute, and
deploy applications into a language-independent format. There is a lot
written about the Kubernetes Patterns and the Kubernetes Effect
on developers and I will keep it short here. Notice though, for
Kubernetes, the smallest primitive to manage is the container and it is
focused on delivering distributed primitives at the container level and
the process model. That means it does a great job on managing the
lifecycle aspects of the applications, health-check, recovery,
deployment, and scaling, but it doesn’t do such a good job improving on
the other aspects of distributed applications which live inside the
container, such as flexible networking, state management, and bindings.
You may point out that Kubernetes has stateful workloads, service
discovery, cron jobs, and other capabilities. That is true, but all of
these primitives are at the container level, and inside the container, a
developer still has to use a language-specific library to access the
more granular capabilities we listed at the beginning of this article.
That is what drives projects like Envoy, Linkerd, Consul, Knative, Dapr,
Camel-K, and others.
Networking
It turns out, the basic networking functionality around service
discovery provided by Kubernetes is a good foundation, but not enough
for modern applications. With the increasing number of microservices and
the faster pace of deployments, the needs for more advanced release
strategies, managing security, metrics, tracing, recovery from errors,
simulating errors, etc. without touching the service, have become
increasingly more appealing and created a new category of software on
its own, called service mesh.
What is more exciting here is the tendency of moving the
networking-related concerns from the service containing the business
logic, outside and into a separate runtime, whether that is sidecar or a
node level-agent. Today, service meshes can do advanced routing, help
to test, handle certain aspects of security, and even speak
application-specific protocols (for example Envoy supports Kafka,
MongoDB, Redis, MySQL, etc.). While service mesh, as a solution, might
not have a wide adoption yet, it touched a real pain point in
distributed systems, and I’m convinced it will find its shape and form
of existence.
In addition to the typical service mech, there are also other projects, such as Skupper,
that confirm the tendency of putting networking capabilities into an
external runtime agent. Skupper solves multi-cluster communication
challenges through a layer 7 virtual network and offers advanced routing
and connectivity capabilities. But rather than embedding Skupper into
the business service runtime, it runs an instance per Kubernetes
namespace which acts as a shared sidecar.
To sum up, container and Kubernetes made a major step forward in the
lifecycle management of the applications. Service mesh and related
technologies hit a real pain point and set the foundation for moving
more responsibilities outside of the application into proxies. Let’s see
what’s next.
State
We listed earlier the main integration primitives that rely on state.
Managing state is hard and should be delegated to specialized storage
software and managed services. That is not the topic here, but using
state, in language-neutral abstractions to aid integration use cases is.
Today, many efforts try to offer stateful primitives behind
language-neutral abstractions. Stateful workflow management is a
mandatory capability in cloud-based services, with examples, such as AWS
Step Functions, Azure Durable Functions, etc. In the container-based
deployments, CloudState and Dapr, both rely on the sidecar model to offer better decoupling of the stateful abstractions in distributed applications.
What I look forward to is also abstracting away all of the stateful
features listed above into a separate runtime. That would mean workflow
management, singletons, idempotency, transaction management, cron job
triggers, and stateful error handling all happening reliably in a
sidecar, (or a host-level agent), rather than living within the service.
The business logic doesn’t need to include such dependencies and
semantics in the application, and it can declaratively request such
behavior from the binding environment. For example, a sidecar can act as
a cron job trigger, idempotent consumer, and workflow manager, and the
custom business logic can be invoked as a callback or plugged in on
certain stages of the workflow, error handling, temporal invocations, or
unique idempotent requests, etc.
Another stateful use case is caching. Whether that is request caching
performed by the service mesh layer, or data caching with something
like Infinispan, Redis, Hazelcast, etc., there are examples of pushing the caching capabilities out of the application’s runtime.
Binding
While we are on the topic of decoupling all distributed needs from
the application runtime, the tendency continues with bindings too.
Connectors, protocol conversions, message transformations, error
handling, and security mediation could all move out of the service
runtime. We are not there yet, but there are attempts in this direction
with projects such as Knative
and Dapr. Moving all of these responsibilities out of the application
runtime will lead to a much smaller, business-logic-focused code. Such a
code would live in a runtime independent from distributed system needs
that can be consumed as prepackaged capabilities.
Another interesting approach is taken by the Apache Camel-K
project. Rather than using an agent runtime to accompany the main
application, this project relies on an intelligent Kubernetes Operator
that builds application runtimes with additional platform capabilities
from Kubernetes and Knative. Here, the single agent is the operator that
is responsible for including the distributed system primitives required
by the application. The difference is that some of the distributed
primitives are added to the application runtime and some enabled in the
platform (which could include a sidecar as well).
Future architecture trends
Looking broadly, we can conclude that the commoditization of
distributed applications, by moving features to the platform level,
reaches new frontiers. In addition to the lifecycle, now we can observe
networking, state abstraction, declarative eventing, and endpoint
bindings also available off-the-shelf, and EIPs are next on this list.
Interestingly enough, the commoditization is using the out-of-process
model (sidecars) for feature extension rather than runtime libraries or
pure platform features (such as new Kubernetes features).
We are now approaching full circle by moving all of the traditional
middleware features (a.k.a ESBs) into other runtimes, and soon, all we
have to do in our service will be to write the business logic.
Traditional middleware and cloud-native platforms overview
Compared to the traditional ESB era, this architecture decouples the
business logic from the platform better, but not yet fully. Many
distributed primitives, such as the classic enterprise integration
patterns (EIPs): splitter, aggregator, filter, content-based router; and
streaming processing patterns: map, filter, fold, join, merge, sliding
windows; still have to be included in the business logic runtime, and
many others depend on multiple distinct and overlapping platform
add-ons.
If we stack up the various cloud-native projects innovating at the
different domains, we end up with a picture such as the following:
Multi-runtime microservices
The diagram here is for illustration purposes only, it purposefully
picks representative projects and maps them to a category of distributed
primitives. In practice, you will not use all of these projects at the
same time as some of them are overlapping and not compatible workload
models. How to interpret this diagram?
Kubernetes and containers made a huge leap in the lifecycle
management of polyglot applications and set the foundation for future
innovations.
Service mesh technologies improved on Kubernetes with advanced
networking capabilities and started tapping into the application
concerns.
While Knative is primarily focused on serverless workloads through
rapid scaling, it also addresses service orchestration and event-driven
binding needs.
Dapr builds on the ideas of Kubernetes, Knative, and Service Mesh
and dives into the application runtimes to tackle stateful workloads,
binding, and integration needs, acting as a modern distributed
middleware.
This diagram is to help you visualize that, most likely in the
future, we will end up using multiple runtimes to implement the
distributed systems. Multiple runtimes, not because of multiple
microservices, but because every microservice will be composed of
multiple runtimes, most likely two — the custom business logic runtime
and the distributed primitives runtime.
Introducing multi-runtime microservices
Here is a brief description of the multi-runtime microservices architecture that is beginning to form.
Do you remember the movie Avatar and the Amplified Mobility Platform
(AMP) "mech suits" developed by scientists to go out into the wilderness
to explore Pandora? This multi-runtime architecture is similar to these
Mecha-suits that give
superpowers to their humanoid drivers. In the movie you have humans
putting on suits to gain strength and access destructive weapons. In
this software architecture, you have your business logic (referred to as
micrologic) forming the core of the application and the sidecar mecha
component that offers powerful out-of-the-box distributed primitives.
The micrologic combined with the mecha capabilities form a multi-runtime
microservice which is using out-of-process features for its distributed
system needs. And the best part is, Avatar 2 is coming out soon to help
promote this architecture. We can finally replace vintage sidecar
motorcycles with awesome mecha pictures at all software conferences ;-).
Let’s look at the details of this software architecture next.
This is a two-component model similar to a client-server
architecture, where every component is separate runtime. It differs from
a pure client-server architecture in that, here, both components are
located on the same host with reliable networking among them that is not
a concern. Both components are equal in importance, and they can
initiate actions in either direction and act as the client or the
server. One of the components is called Micrologic, and it holds the
very minimal business logic stripped out of almost all of the
distributed system concerns. The other accompanying component is the
Mecha, and it provides all of the distributed system features we have
been talking about through the article (except lifecycle which is a
platform feature).
There might be a one-to-one deployment of the Micrologic and the
Mecha (known as the sidecar model), or it can be one shared Mecha with a
few Micrologic runtimes. The first model is most appropriate on
environments, such as Kubernetes, and the latter on the edge
deployments.
Micrologic runtime characteristics
Let’s briefly explore some of the characteristics of the Micrologic runtime:
The Micrologic component is not a microservice on its own. It
contains the business logic that a microservice would have, but that
logic can only work in combination with the Mecha component. On the
other hand, microservices are self-contained and do not have pieces of
the overall functionality or part of the processing flow spread into
other runtimes. The combination of a Micrologic and its Mecha
counterpart form a Microservice.
This is not a function or serverless architecture either. Serverless is mostly known
for its managed rapid scaling up and scale-to-zero capabilities. In the
serverless architecture, a function implements a single operation as
that is the unit of scalability. In that regard, a function is different
from a Micrologic which implements multiple operations, but the
implementation is not end-to-end. Most importantly, the implementation
of the operations is spread over the Mecha and the Micrologic runtimes.
This is a specialized form of client-server architecture, optimized
for the consumption of well-known distributed primitives without
coding. Also, if we assume that the Mecha plays the server role, then
each instance has to be specifically configured to work with the
individual client(s). It is not a generic server instance aiming to
support multiple clients at the same time as a typical client-server
architecture.
The user code in the Micrologic does not interact directly with
other systems and does not implement any distributed system primitives.
It interacts with the Mecha over de facto standards, such as HTTP/gRPC, CloudEvents
spec, and the Mecha communicates with other systems using enriched
capabilities and guided by the configured steps and mechanisms.
While the Micrologic is responsible only for implementing the
business logic stripped out of distributed system concerns, it still has
to implement a few APIs at a minimum. It has to allow the Mecha and the
platform to interact with it over predefined APIs and protocols (for
example, by following the cloud-native design principles for Kubernetes deployments).
Mecha runtime characteristics
Here are some of the Mecha runtime characteristics:
The Mecha is a generic, highly configurable, reusable component offering distributed primitives as off-the-shelf capabilities.
Each instance of the Mecha has to be configured to work with one
Micrologic component (the sidecar model) or configured to be shared with
a few components.
The Mecha does not make any assumption about the Micrologic
runtime. It works with polyglot microservices or even monolithic systems
using open protocols and formats, such as HTTP/gRPC, JSON, Protobuf,
CloudEvents.
The Mecha is configured declaratively with simple text formats,
such as YAML, JSON, which dictates what features to be enabled and how
to bind them to the Micrologic endpoints. For specialized API
interactions, the Mechan can be additionally supplied with specs, such
as OpenAPI, AsyncAPI, ANSI-SQL, etc. For stateful workflows, composed of multiple processing steps, a spec, such as Amazon State Language, can be used. For stateless integrations, Enterprise Integration Patterns (EIPs) can be used with an approach similar to the Camel-K YAML DSL.
The key point here is that all of these are simple, text-based,
declarative, polyglot definitions that the Mecha can fulfill without
coding. Notice that these are futuristic predictions, currently, there
are no Mechas for stateful orchestration or EIPs, but I expect existing
Mechas (Envoy, Dapr, Cloudstate, etc) to start adding such capabilities
soon. The Mecha is an application-level distributed primitives
abstraction layer.
Rather than depending on multiple agents for different purposes,
such as network proxy, cache proxy, binding proxy, there might be a
single Mecha providing all of these capabilities. The implementation of
some capabilities, such as storage, message persistence, caching, etc.,
would be plugged in and backed by other cloud or on-premise services.
Some distributed system concerns around lifecycle management make
sense to be provided by the managing platform, such as Kubernetes or
other cloud services, rather than the Mecha runtime using generic open
specifications such as the Open App Model.
What are the main benefits of this architecture?
The benefits are loose coupling between the business logic and the
increasing list of distributed systems concerns. These two elements of
software systems have completely different dynamics. The business logic
is always unique, custom code, written in-house. It changes frequently,
depending on your organizational priorities and ability to execute. On
the other hand, the distributed primitives are the ones addressing the
concerns listed in this post, and they are well known. These are
developed by software vendors and consumed as libraries, containers or
services. This code changes depending on vendor priorities, release
cycles, security patches, open-source governing rules, etc. Both groups
have little visibility and control over each other.
Business logic and distributed system concerns coupling in application architectures
Microservices principles help decouple the different business domains
by bounded contexts where every microservice can evolve independently.
But microservices architecture does not address the difficulties coming
from coupling the business logic with middleware concerns. For certain
microservices that are light on integration use cases, this might not be
a big factor. But if your domain involves complex integrations (which
is increasingly becoming the case for everybody), following the
microservices principles will not help you protect from coupling with
the middleware. Even if the middleware is represented as libraries you
include in your microservices, the moment you start migrating and
changing these libraries, the coupling will become apparent. And the
more distributed primitives you need, the more coupled into the
integration platform you become. Consuming middleware as a separate
runtime/process over a predefined API rather than a library helps loose
coupling and enables the independent evolution of each component.
This is also a better way to distribute and maintain complex
middleware software for vendors. As long as the interactions with the
middleware are over inter-process communication involving open APIs and
standards, the software vendors are free to release patches and upgrades
at their pace. And the consumers are free to use their preferred
language, libraries, runtimes, deployments methods, and processes.
What are the main drawbacks of this architecture?
Inter-process communication. The fact that the business logic and the
middleware mechanics (you see where the name comes from) of the
distributed systems are in different runtimes and that requires an HTTP
or gRPC call rather than an in-process method call. Notice though, this
is not a network call that is supposed to go to a different machine or
datacenter. The Micrologic runtime and the Mecha are supposed to be
colocated on the same host with low latency and minimal likelihood of
network issues.
Complexity. The next question is, whether it is worth the complexity
of development, and maintaining such systems for the gained benefits. I
think the answer will be increasingly inclining towards yes. The
requirements of distributed systems and the pace of release cycles are
increasing. And this architecture optimizes for that. I wrote some time
ago that the developers of the future will have to be with hybrid development skills.
This architecture confirms and enforces further this trend. Part of the
application will be written in a higher-level programming language, and
part of the functionality will be provided by off-the-shelf components
that have to be configured declaratively. Both parts are inter-connected
not at compile-time, or through in-process dependency injection at
startup time, but at deployment time, through inter-process
communications. This model enables a higher rate of software reuse
combined with a faster pace of change.
What comes after microservices are not functions
Microservices architecture has a clear goal. It optimizes for change.
By splitting applications into business domains, this architecture
offers the optimal service boundary for software evolution and
maintainability through services that are decoupled, managed by
independent teams, and released at an independent pace.
If we look at the programming model of the serverless architecture,
it is primarily based on functions. Functions are optimized for
scalability. With functions, we split every operation into an
independent component so that it can scale rapidly, independently, and
on-demand. In this model, the deployment granularity is a function. And
the function is chosen because it is the code construct that has an
input whose rate correlates directly to the scaling behavior. This is an
architecture that is optimized for extreme scalability, rather than
long term maintainability of complex systems.
What about the other aspect of Serverless, which comes from the
popularity of AWS Lambda and its fully managed operational nature? In
this regard, "AWS Serverless" optimizes for speed of provisioning for
the expense of lack of control and lock-in. But the fully managed aspect
is not application architecture, it is a software consumption model. It
is an orthogonal functionally, similar to consuming a SaaS-based
platform which in an ideal world should be available for any kind of
architecture whether that is monolithic, microservices, mecha or
functions. In many ways, AWS Lambda resembles a fully managed Mecha
architecture with one big difference: Mecha does not enforce the
function model, instead it allows a more cohesive code constructs around
the business domain, split from all middleware concerns.
Application architecture optimizations
Mecha architecture, on the other hand, optimizes microservices for
middleware independence. While microservices are independent of each
other, they are heavily dependent on embedded distributed primitives.
The Mecha architecture splits these two concerns into separate runtimes
allowing their independent release by independent teams. This decoupling
improves day-2 operations (such as patching and upgrades) and the long
term maintainability of the cohesive units of business logic. In this
regard, Mecha architecture is a natural progression of the microservices
architecture by splitting software based on the boundaries that cause
most friction. That optimization provides more benefits in the form of
software reuse and evolution than the function model, which optimizes
for extremely scalability at the expense of over-distribution of code.
Conclusion
Distributed applications have many requirements. Creating effective
distributed systems requires multiple technologies and a good approach
to integration. While traditional monolithic middleware provided all of
the necessary technical features required by distributed systems, it
lacked the ability to change, adapt, and scale rapidly, which was
required by the business. This is why the ideas behind
microservices-based architectures contributed to the rapid
popularization of containers and Kubernetes; with the latest
developments in the cloud-native space, we are now coming full circle by
moving all of the traditional middleware features into the platform and
off-the-shelf auxiliary runtimes.
This commoditization of application features is primarily using the
out-of-process model for feature extension, rather than runtime
libraries or pure platform features. That means that in the future it is
highly likely that we will use multiple runtimes to implement
distributed systems. Multiple runtimes, not because of multiple
microservices, but because every microservice will be composed of
multiple runtimes; a runtime for the custom micro business logic, and an
off-the-shelf, configurable runtime for distributed primitives.
This article was originally published on InfoQ here.










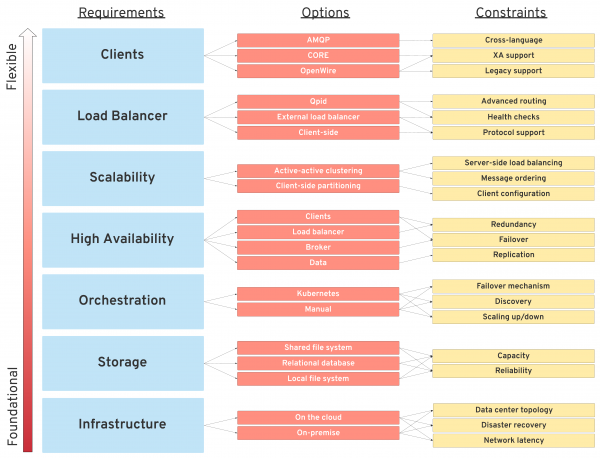

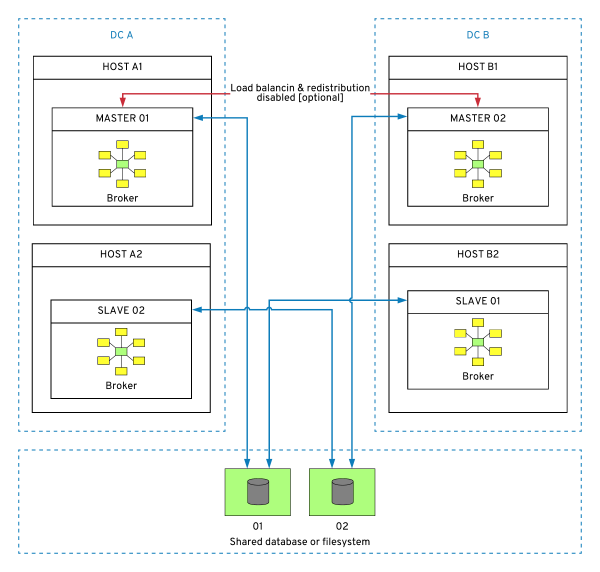






 microservices architecture")


")





